Session 7 : Error Handling and Logging in SSIS
Let us now add some more features to our package. We would now add Event handling and Logging to our package created. Before doing that, let us see what do the two means.
Event Handling: As the name suggests, based on certain event, we would like to take some action (handle the event) the way we want. We may want to shoot an email in case of an error or failure in the package. Or we might want to truncate a table once the ETL is completed.
Logging: Again, as the name suggests, we need to log the events that are happening in our package. For example, we need to know which all tasks have executed successfully or have failed. In case of failure, what was the error message etc.
The difference between the two is that in Logging, we merely record the events and any message generated by the system to a log file, table etc. While in case of Event Handling, we may wish to take additional action based on the events.
Having said this, we shall start the demo on Event Handling in SSIS.
We will go back to our package created earlier. It has just a data flow task to move the data from Flat file to a database table. What we will do is to introduce an error in the package and then handle the event in a way we want.
Here, we have the package ready and the data flow task as mentioned above (see image below). Please look along and do as explained along with the images.
In the above Data Flow Task, we have just a Flat File Source and an OLEDB Destination (see the image below).
Now we start with the Event Handling. Take a look at the figure below. You will notice we have now moved to a new tab Event Handlers. You will see two dropdown boxes, one stating Executable and other stating Event Handler.
Click on the 2 dropdowns and you would see the values as in the figure below. Executables are all the tasks that you see on the Control Flow. While Events are the possible events that can happen on the above executables. I select the Data Flow task in the Executable and for handling I will select OnError event.
Once we make the above selection, we will see the screen below:
Click on the hyperlink and the screen would look like the one in the figure below:
The point to be noted is that we can have all the tasks that we have in Control Flow in the event handler. We can have a kind of small package here, which does its own ETL. Event handlers are very powerful and useful tool available to the SSIS developers.
We have selected the task as Data Flow Task and the event we want to handle is onError. This means that when an error will occur this event will be fired and what task we drop in the above area (as in the figure above) will be executed if the Data Flow task fails.
To achieve this we need to introduce an error in the package. All you need to do to achieve this is to open the flat file connection we have and change the file name to a non-existing name. Now when the package executes, it will not find the file and the package will fail. Now, what we want is whenever this happens or other error occurs, an entry per error should be recorded in a log table we have.
Use the query below to create the log table
1.CREATE TABLE [dbo].[Log](
2.[ID] [int] IDENTITY(1,1) NOT NULL,
3.[PackageID] [uniqueidentifier] NULL,
4.[Error] [nvarchar](max) NULL,
5.[Source] [nvarchar](100) NULL,
6.[PackageName] [nvarchar](100) NULL
7.) ON [PRIMARY]
Let is now get back to our package.
Double click the Execute SQL Task to open the Editor window as in figure below
Set up the Connection String and use the below Insert Query in the SQL Statement.
1.INSERT INTO [dbo].[Log]
2.([PackageID]
3.,[Error]
4.,[Source]
5.,[PackageName])
6.VALUES
7.(?,?,?,?)
The question marks used above are the parameters we pass to the above query. Based on the mapping we do in the next step, these will get the value.
Next, go to the Parameter Mapping tab as shown in the next figure. I will not the talking on all the details you see on this tab. We will cover it in later section. As of now, I would ask you to set up your Parameter Mapping exactly as you see here. One point to note here is that we are using the system variables and not user variables to map the values for the parameters. Here you will see how useful the system variables are. Once you have set up parameter mapping, click OK. You are done.
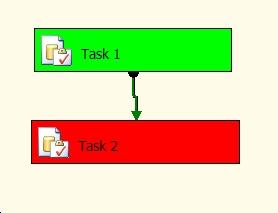
Now execute the package by clicking F5. You will see that the package fails and the Data Flow Task goes red (see figure below). If this does not happen and the package is executed successfully, ensure that you have changed the name of the file in the flat file connection manager to a non-existent file name.
If you double click the Data Flow Task, you will notice that the Flat file Source has failed. I hope you know the reason.
If you now go to the Event Handler tab, you will notice that the Execute SQL Task that we had put here has executed successfully.
Go to the Data base where you created the Log table and select the records from the log table.
You should the following output:
Now instead of the execute SQL task, you could have a send mail task to notify the admin etc.
LOGGING
We will now see how to implement logging in SSIS Packages. This is rather simple to implement.
Go to the SSIS Menu and select logging from there.
We have various options to save the SSIS Logging (see figure below). We can save the logs to Windows Event log, a Text File, XML File, SQL Server Table or SQL Profiler. The choice is yours, choose the one you feel perfect for your need. I will use SQL Server Table as the provider. Select theProvider as SQL Server and click the Add button next to it.
Select the SQL Connection where you want to log the events. I will use the same Database Connection I used in the Data Flow Task. You can have separate database for logging as practiced in real life scenarios. Also, check the checkbox on the left side else, the logging will not occur. You need to do the log for the entire package; you could select the executable for which you want to enable to logging. I have selected the entire package for logging.
Once you are done with the above setting, go to the Details tab. Here, you will see the various events that you have for each executable. Select the events you wish to log. Generally we log the following events:
- OnValidate
- OnPreExecute
- OnWarning
- OnError
- OnPostExecute
We are done!! Execute the package, go to the data base that you configured for logging above and fire this query:
1.SELECT * FROM dbo.sysssislog
This table is automatically created, you can change the table name but that will be shown in later articles. Check the output you get for the above.
In the next article we will take a look at the various ways to execute a package.